Revealing Toronto's Best Jobs: What Salary Data Tells Us
Exploring Toronto’s Job Landscape with Data Science: Key Findings on Salaries and Job Prospects
TLDR
In this article, we will explore:
- Top 10 Jobs by Median Salary: A list of the top 10 highest-paying jobs based on the median salary.
- Top 10 High Potential Jobs: Jobs with the highest salaries at the 90th percentile.
- Salary Spread Analysis: Calculation of salary spread (difference between 90th and 10th percentiles) to identify low-risk jobs. Interestingly, low-risk jobs often correlate with lower pay.
- Annual Salary Conversion: All hourly wages are converted to yearly salaries, assuming a 37.5-hour workweek and 52 weeks per year.
- Job Prospect Forecast: Data on job prospects over the next three years, categorized into Very Good, Good, Moderate, Limited, Very Limited, and Varied.
- Jobs with Highest Number of Workers: A table listing jobs with the largest workforce.
How to Obtain and Analyze Job Market Data in Toronto
Step 1: Downloading the Data
To get started, download the relevant data from the Government of Canada using this link.
Step 2: Loading the Data in Python
Once downloaded, load the data into a Python DataFrame:
import pandas as pd
df_raw = pd.read_csv("raw saleris.csv")
df_raw.head()Step 3: Filtering and Cleaning the Data
Focus on the City of Toronto by filtering the data, dropping unnecessary columns, and performing some basic data cleaning:
df_toronto = df_raw[df_raw["ER_Name"] =="Toronto"].copy()
df_toronto.reset_index(inplace=True, drop=True)
df_toronto["NOC_CNP"] = [int(item.split("_")[1]) for item in df_toronto["NOC_CNP"]]
df_toronto.drop(["NOC_TITLE_FRA",
"prov",
"ER_Code_Code_RE",
"ER_Name", "Nom_RE",
"Data_Source_F",
"Wage_Comment_F",
"Data_Source_E",
"Reference_Period",
"Revision_Date_Date_revision",
"Wage_Comment_E"
], axis=1, inplace=True)
df_toronto.rename(columns={"NOC_CNP": "NOC Code",
"NOC_TITLE_ENG": "NOC_TITLE",
"Low_Wage_Salaire_Minium": "Low_Wage",
"Median_Wage_Salaire_Median": "Median_Wage",
"High_Wage_Salaire_Maximal": "High_Wage",
"Average_Wage_Salaire_Moyen": "Average_Wage",
"Annual_Wage_Flag_Salaire_annuel": "Annual_Wage_Flag",
}, inplace=True)
pd.options.display.float_format = "{:,.2f}".format
df_toronto.head()Step 4: Gathering Job Market Insights
To enhance our analysis, we need data on the number of individuals working in each job title in Toronto and the job prospects for the next three years. This information is available on the Job Bank of Canada website, but it's not directly downloadable, so we'll use web crawling.
Step 4.1: Extracting NOC Codes
First, create a DataFrame of NOC codes by web scraping from this link
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import pandas as pd
# extracting NOC codes
url_noc = "https://www.canada.ca/en/immigration-refugees-citizenship/services/immigrate-canada/express-entry/eligibility/find-national-occupation-code.html#wb-auto-4"
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
driver = webdriver.Chrome(options=chrome_options)
driver.get(url_noc)
time.sleep(5)
num_entries = driver.find_element(By.TAG_NAME, value="select")
num_entries.click()
num_options = driver.find_elements(By.TAG_NAME, value="option")
num_options[-1].click()
dict_data = {}
dict_data["TEER Category"], dict_data["NOC Code"], dict_data["Class Title"] = [[] for i in range(3)]
for i in range(6):
cells = driver.find_elements(By.CSS_SELECTOR, value="#wb-auto-4 td")
cells_text = [item.text for item in cells]
dict_data["TEER Category"] += cells_text[::3]
dict_data["NOC Code"] += cells_text[1::3]
dict_data["Class Title"] += cells_text[2::3]
if i <5:
next_page = driver.find_element(By.ID, value="wb-auto-4_next")
next_page.click()
driver.close()
df_noc = pd.DataFrame(dict_data)
df_noc.to_csv("NOC Codes.csv")
df_noc Step 4.2: Extracting Employment Data
Next, extract the number of individuals working in each job title in Toronto. Navigate to the job profiles section on Job Bank Canada, search for a job title and location (e.g., Toronto), and retrieve the job prospect data:


We also need to perform web crawling to extract this data using the code below.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
import pandas as pd
import numpy as np
# Extracting number of people working in each noc code
df_noc = pd.read_csv("Noc Codes.csv")
df_noc.drop("Unnamed: 0", axis=1, inplace=True)
url = "https://www.jobbank.gc.ca/career-planning/search-job-profile"
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
driver = webdriver.Chrome(options=chrome_options)
driver.maximize_window()
dict_num_people = {"Job Title":[],
"NOC Code":[],
"# of working individuals": [],
"Prospect": [],
}
start = len(dict_num_people["Job Title"])
for i in range(start,len(df_noc)):
success = False
driver.get(url)
if i==start:
try:
warning_close =driver.find_element(By.ID, value="j_id_2s:outOfCanadaCloseBtn")
warning_close.click()
time.sleep(3)
except:
print("No warning poped up")
while not success:
try:
time.sleep(3)
job_input = driver.find_element(By.ID, value="jmr-search:occupationInput")
noc_code = df_noc.loc[i]["NOC Code"]
job_input.send_keys(str(noc_code))
time.sleep(3)
job_suggestion = driver.find_element(By.CLASS_NAME, value="tt-selectable")
job_suggestion.click()
city_input = driver.find_element(By.ID, value="jmr-search:cityPostalCodeInput")
city_input.send_keys("Toronto")
time.sleep(3)
city_suggestion = driver.find_element(By.XPATH, value='//*[@id="jmr-search"]/div[2]/div/span[1]/div/div/p')
city_suggestion.click()
submit_btn = driver.find_element(By.ID, value="searchSubmit")
submit_btn.click()
prospect_btn = driver.find_element(By.ID, value="j_id_2n_2_32")
prospect_btn.click()
prospect = driver.find_element(By.CLASS_NAME, value="outlooknote").text
bullet_points = driver.find_elements(By.CSS_SELECTOR, value=".col-sm-9 ul li")
if len(bullet_points) != 0:
bullet_points = [point.text for point in bullet_points]
bullet_point = [point for point in bullet_points if "Approximately" in point]
if len(bullet_point) !=0:
num_people = int(bullet_point[0].split()[1].replace(",",""))
else:
num_people = np.nan
else:
num_people = np.nan
dict_num_people["Job Title"] += [df_noc.loc[i]["Class Title"]]
dict_num_people["NOC Code"] += [noc_code]
dict_num_people["# of working individuals"] += [num_people]
dict_num_people["Prospect"] += [prospect]
success = True
except:
job_input.clear()
city_input.clear()
print(f"Error processing item {i}")
df_num_people = pd.DataFrame(dict_num_people)
df_num_people.to_csv("num_of_people.csv", index=False)
pd.options.display.float_format = "{:,.0f}".format
df_num_peopleStep 5: Merging Data and Analyzing Results
Merge the two DataFrames for a comprehensive analysis:
df_merged = pd.merge(df_toronto, df_num_people.drop("Job Title", axis=1), on="NOC Code")
# Making all salaries yearly
columns_to_multiply = ["Low_Wage", "Median_Wage", "High_Wage", "Average_Wage"]
multiplier = (37.5 * 52)
rows_to_include = df_merged["Annual_Wage_Flag"] ==0
df_merged.loc[rows_to_include, columns_to_multiply] = df_merged.loc[rows_to_include, columns_to_multiply].multiply(multiplier)
df_merged.drop("Annual_Wage_Flag", axis=1, inplace=True)
df_mergedStep 6: Calculating Average Salary
The average salary in Toronto is calculated as below:
average = sum(df_clean["# of working individuals"] * df_clean["Average_Wage"])/sum(df_clean["# of working individuals"])
averageStep 7: Sorting and Presenting Results
Now, if we do some sorting on the data frame, we can have the results below:

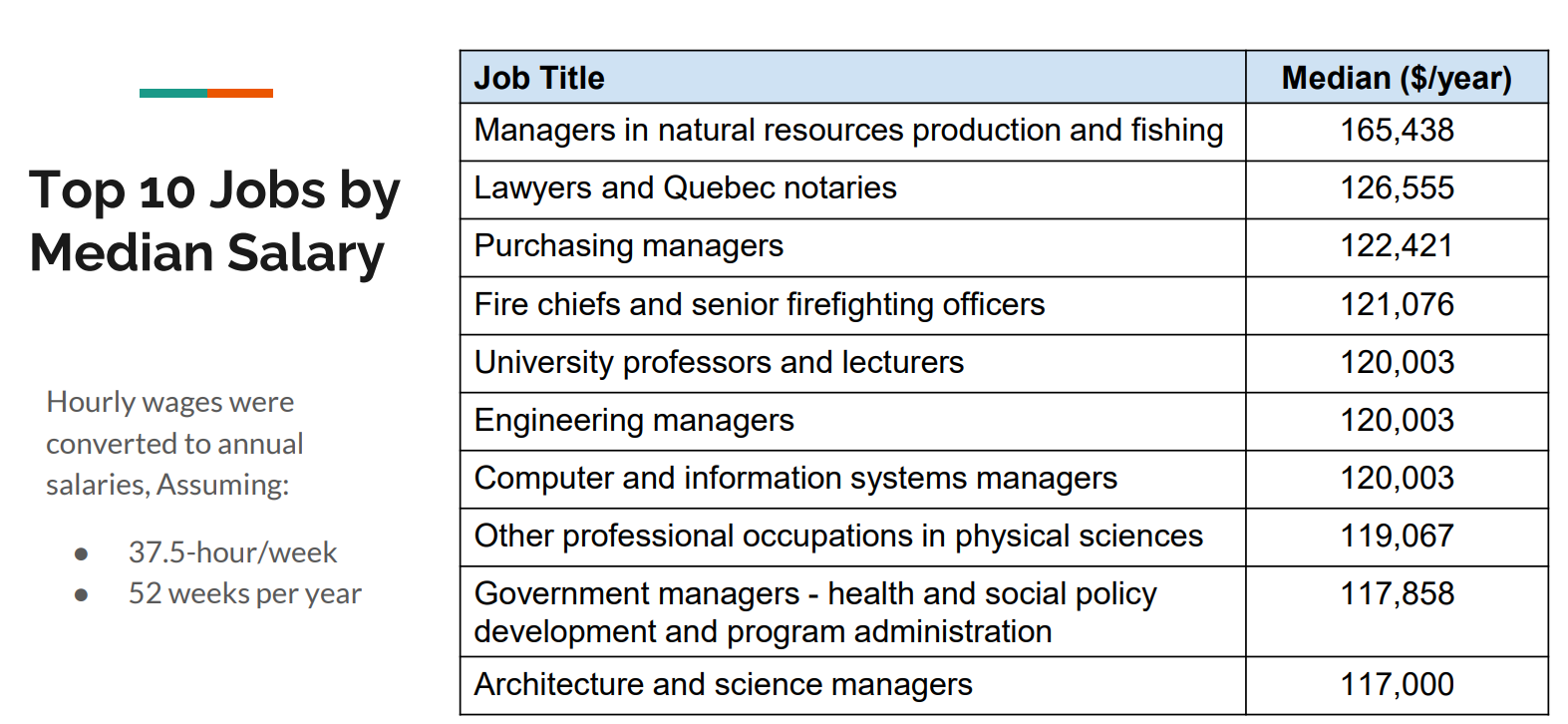
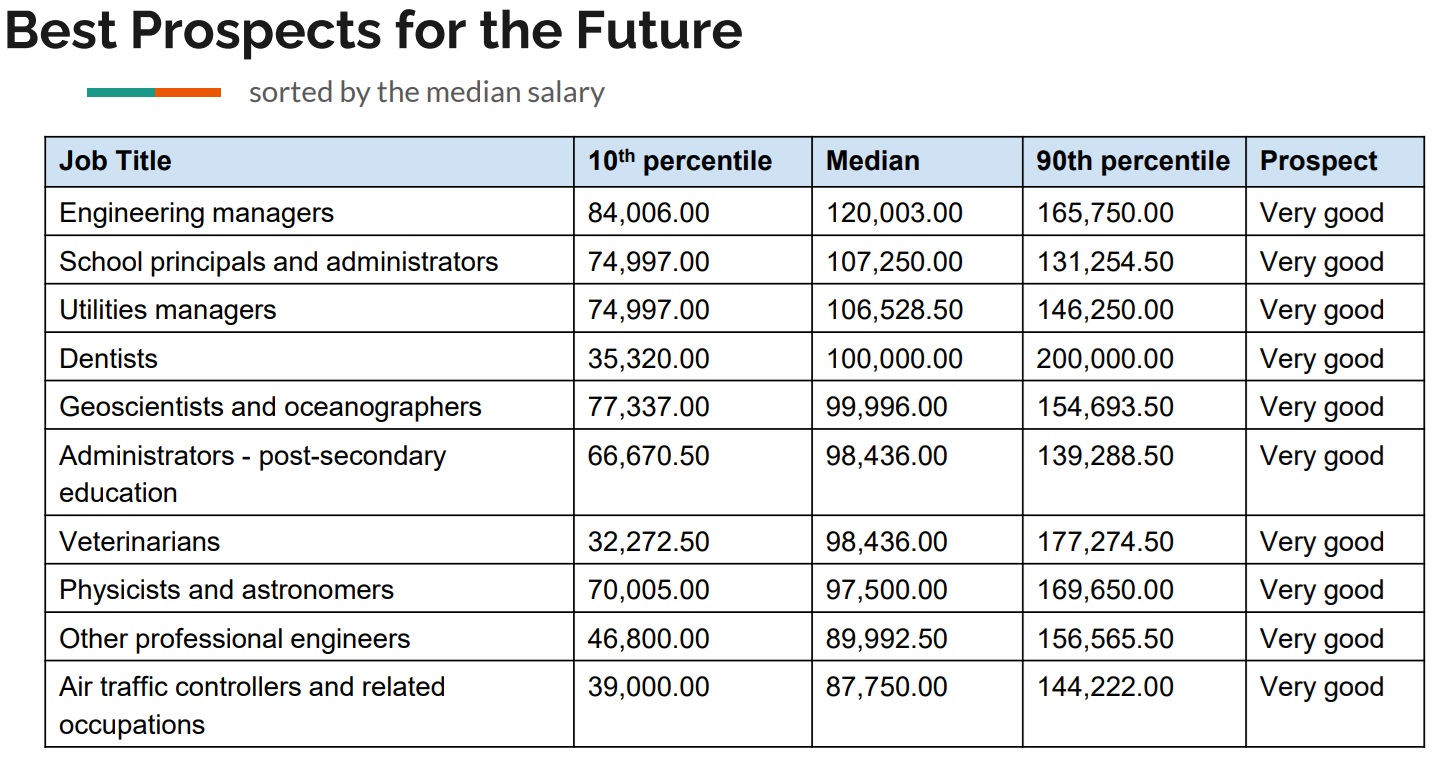
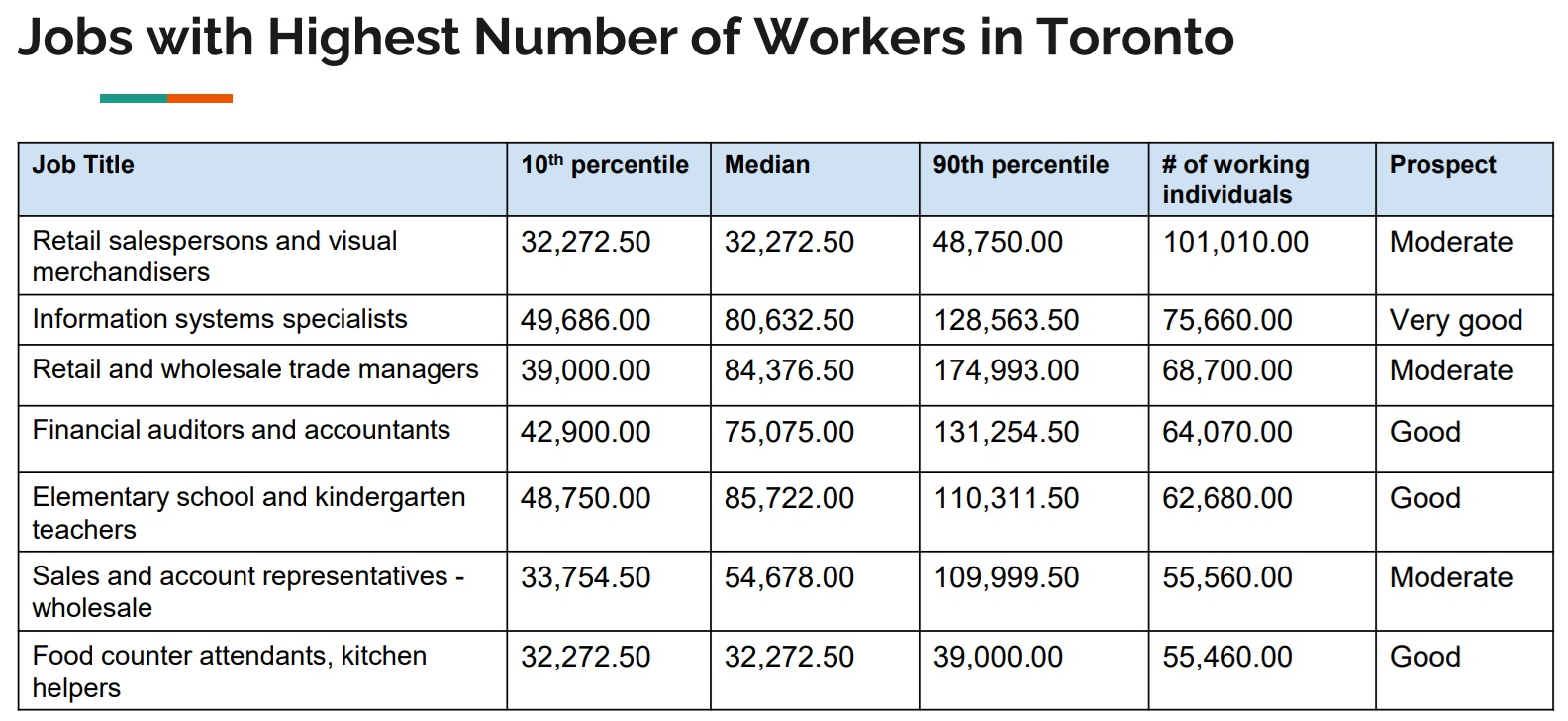
Full Code Reference
For the full code and further details, visit my GitHub repository:
https://github.com/talezadeh/Salaries_in_Toronto